kirra-docs
CSV Import
Kirra reads blast holes from CSV files using its BlastHole CSV family — a set of preset column layouts dispatched on column count. Choose your preset in the Import dialog or use Custom CSV if your file does not match a preset.
Source of truth: the Kirra wiki BlastHole CSV Format page is generated from the parser in
src/fileIO/TextIO/BlastHoleCSVParser.js.
How to Import a CSV
- Open the Left Sidenav (☰ in the App Navigation Bar)
- Under File Management, click Import
- In the Import dialog, stay on the Kirra tab
- Choose Holes CSV / TXT (preset columns) and pick the column-count preset from the dropdown (default 14 Column)
- Click Open and select your
.csvfile
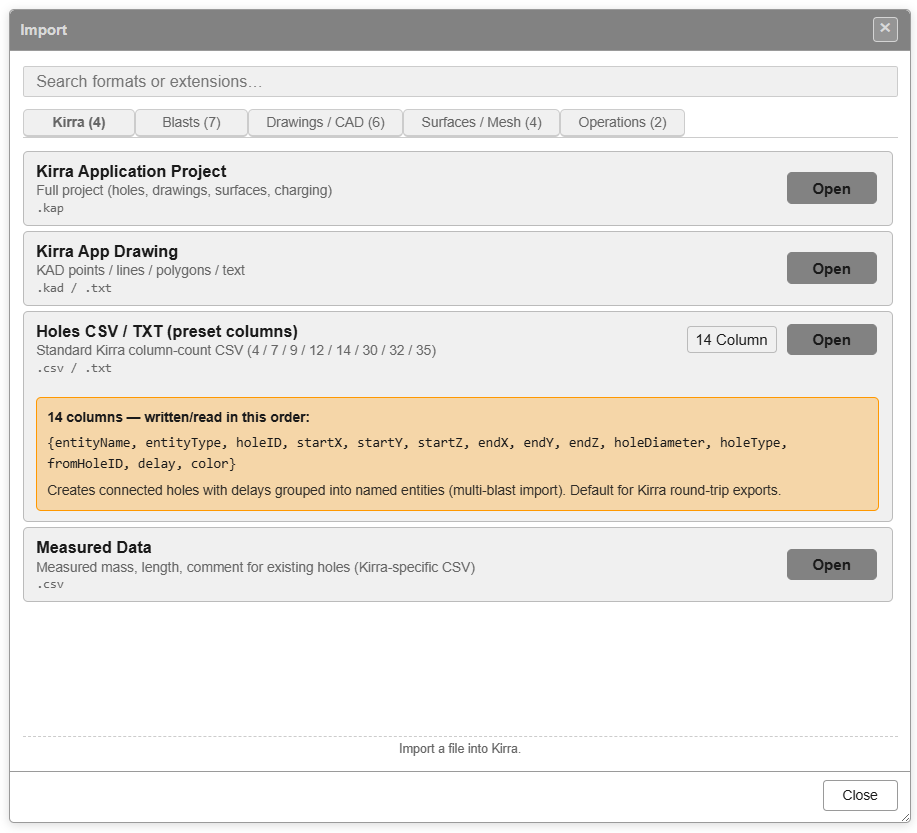 The Holes CSV / TXT row shows the active column-count preset (14 in this screenshot).
The Holes CSV / TXT row shows the active column-count preset (14 in this screenshot).
If your file does not match any preset, switch to Custom CSV on the Blasts tab — see Custom CSV Import below.
BlastHole CSV — eight preset variants
The parser dispatches strictly on column count. Pick the preset that matches your file exactly.
| Cols | Layout | Carries |
|---|---|---|
| 4 | holeID, X, Y, Z |
Collar only — toe defaults to collar (dummy holes) |
| 7 | + endX, endY, endZ |
Collar → toe vector |
| 9 | + holeDiameter, holeType |
Diameter (mm) and hole type |
| 12 | + fromHoleID, delay, color |
Tying / delay / colour (single entity) |
| 14 | entityName, entityType, … (rest as 12-col) |
Multi-entity grouping — recommended round-trip format |
| 30 | Own column order — see below | Full design + as-drilled data (grade, subdrill, bench, angle, bearing, timing, measured-*) |
| 32 | 30-col + rowID, posID |
Row / position bookkeeping |
| 35 | 32-col + burden, spacing, connectorCurve |
Complete — every parsed field |
30-col is not “14 + extras”. Cols 1-9 match the 14-col layout, but from col 10 onward the order diverges — grade, subdrill, and bench come before
holeDiameter. See the 30-Column section for the exact order.
4-Column (Collar Only)
Creates collar-only holes — toe coordinates default to the collar position.
| Column | Field |
|---|---|
| 1 | holeID |
| 2 | X — collar Easting (m) |
| 3 | Y — collar Northing (m) |
| 4 | Z — collar Elevation (m) |
H001,477750.5,6771850.2,335.0
H002,477755.5,6771850.2,335.0
7-Column (Collar + Toe)
Full 3D hole geometry — collar plus toe.
| Column | Field |
|---|---|
| 1 | holeID |
| 2-4 | Collar X / Y / Z |
| 5-7 | Toe endX / endY / endZ |
H001,477750.5,6771850.2,335.0,477751.2,6771849.8,320.0
9-Column (+ Diameter + Type)
Adds hole diameter and hole-type classification.
| Column | Field |
|---|---|
| 1 | holeID |
| 2-4 | Collar X / Y / Z |
| 5-7 | Toe endX / endY / endZ |
| 8 | holeDiameter (mm) |
| 9 | holeType — e.g. Production, Buffer, Presplit, Trim |
12-Column (+ Timing + Colour)
Adds the timing connection back to its source hole, the delay, and a display colour.
| Column | Field |
|---|---|
| 1 | holeID |
| 2-4 | Collar X / Y / Z |
| 5-7 | Toe endX / endY / endZ |
| 8 | holeDiameter (mm) |
| 9 | holeType |
| 10 | fromHoleID — upstream hole in the timing chain |
| 11 | delay — milliseconds relative to fromHoleID |
| 12 | color — #RRGGBB hex, or a named colour like red / blue |
fromHoleIDform: in legacy single-entity files, just the holeID (e.g.H001). In multi-entity files (14-col), useentityName:::holeID(e.g.Pattern_A:::H001).
14-Column (Kirra Standard — Recommended)
Same fields as 12-col but prefixed with the entity name (blast pattern) and entity type. This is the recommended round-trip format.
| Column | Field |
|---|---|
| 1 | entityName — blast pattern name (e.g. Pattern_A) |
| 2 | entityType — hole for blast holes |
| 3 | holeID |
| 4-6 | Collar X / Y / Z |
| 7-9 | Toe endX / endY / endZ |
| 10 | holeDiameter (mm) |
| 11 | holeType |
| 12 | fromHoleID — use the entityName:::holeID form |
| 13 | delay (ms) |
| 14 | color |
Pattern_A,hole,H001,477750.5,6771850.2,335.0,477751.2,6771849.8,320.0,115,Production,,0,#FF0000
Pattern_A,hole,H002,477755.5,6771850.2,335.0,477756.2,6771849.8,320.0,115,Production,Pattern_A:::H001,25,#FF0000
30-Column (Full Design + As-Drilled)
The 30-column layout is not “14-col + extras”. It has its own column order — grade, subdrill, and bench come before holeDiameter, and the measured / as-drilled fields fill the tail.
| Column | Field | Notes |
|---|---|---|
| 1 | entityName |
Blast pattern name |
| 2 | entityType |
hole for blast holes |
| 3 | holeID |
|
| 4-6 | startX, startY, startZ |
Collar |
| 7-9 | endX, endY, endZ |
Toe |
| 10-12 | gradeX, gradeY, gradeZ |
Grade point — computed from subdrill on read, re-derived on write |
| 13 | subdrillAmount |
Vertical delta-Z (m), not along-hole |
| 14 | subdrillLength |
Along-hole subdrill (m) |
| 15 | benchHeight |
Bench height (m) |
| 16 | holeDiameter |
mm |
| 17 | holeType |
e.g. Production |
| 18 | fromHoleID |
Upstream tying hole (use entityName:::holeID) |
| 19 | delay |
Relative milliseconds. Accepts na / n/a / null / nan (case-insensitive) → stored as NaN for the harness-wire / null-connector convention |
| 20 | color |
#RRGGBB or named colour |
| 21 | holeLength |
Calculated (m) |
| 22 | holeAngle |
Angle from vertical (0 = vertical) |
| 23 | holeBearing |
Azimuth clockwise from North |
| 24 | holeTime |
Hole fire time |
| 25 | measuredLength |
As-drilled length (m) |
| 26 | measuredLengthTimeStamp |
When the length was measured |
| 27 | measuredMass |
As-loaded mass (kg) |
| 28 | measuredMassTimeStamp |
When the mass was measured |
| 29 | measuredComment |
Free-text comment |
| 30 | measuredCommentTimeStamp |
When the comment was recorded |
Two subdrill fields:
subdrillAmountis the vertical drop below grade (Δz).subdrillLengthis the same value projected along the hole vector. Both are written on export so importers can use whichever convention they prefer.
Measured timestamps: Each measured field has a paired
…TimeStampcolumn. Empty timestamps are allowed.
32-Column (+ Row / Position)
30-column layout plus row and position bookkeeping.
| Column | Field |
|---|---|
| 31 | rowID |
| 32 | posID |
Empty rowID / posID parse as null. Holes with null or 0 row/pos are treated as unassigned and may be processed by smart row detection.
35-Column (Complete)
Full lossless export — every field the parser recognises.
| Column | Field |
|---|---|
| 33 | burden (m) |
| 34 | spacing (m) |
| 35 | connectorCurve |
For a full project save, prefer KAP — it carries every project state (charging, timing constructs, drawings, surfaces, layers) instead of just the holes.
Header rows
A header row is detected only when all of columns 3-5 (collar X/Y/Z) on the first row are non-numeric. If your file has a header that doesn’t match this rule, the parser may treat it as a data row.
If you have an unusual header layout, use Custom CSV instead — it does header-driven field mapping.
Custom CSV Import
If your CSV does not match a preset (different column order, different field names, extra columns), use Custom CSV on the Blasts tab of the Import dialog. Custom CSV also handles .txt and configurable delimiters (comma, tab, pipe, semicolon).
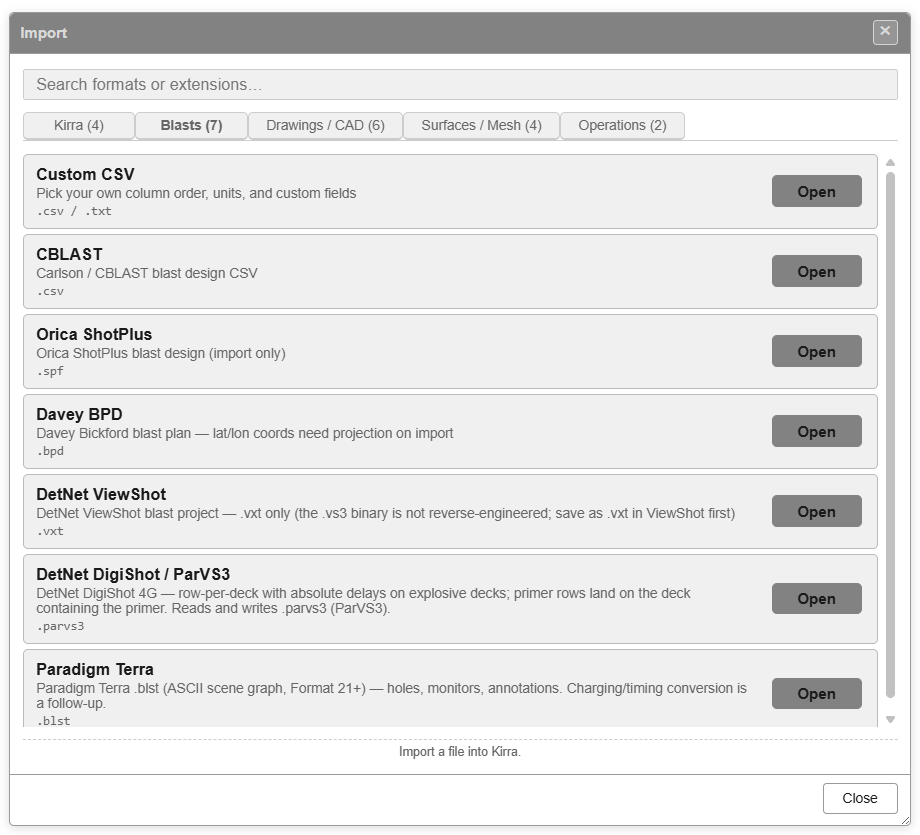 Custom CSV is the first entry on the Blasts tab — “Pick your own column order, units, and custom fields”.
Custom CSV is the first entry on the Blasts tab — “Pick your own column order, units, and custom fields”.
- Left Sidenav → Import
- Blasts tab → Custom CSV → click Open
- Choose your
.csvor.txtfile - The Import CSV: Map Columns dialog opens — review the auto-detected mapping (or override manually) and click Import
The Map Columns dialog
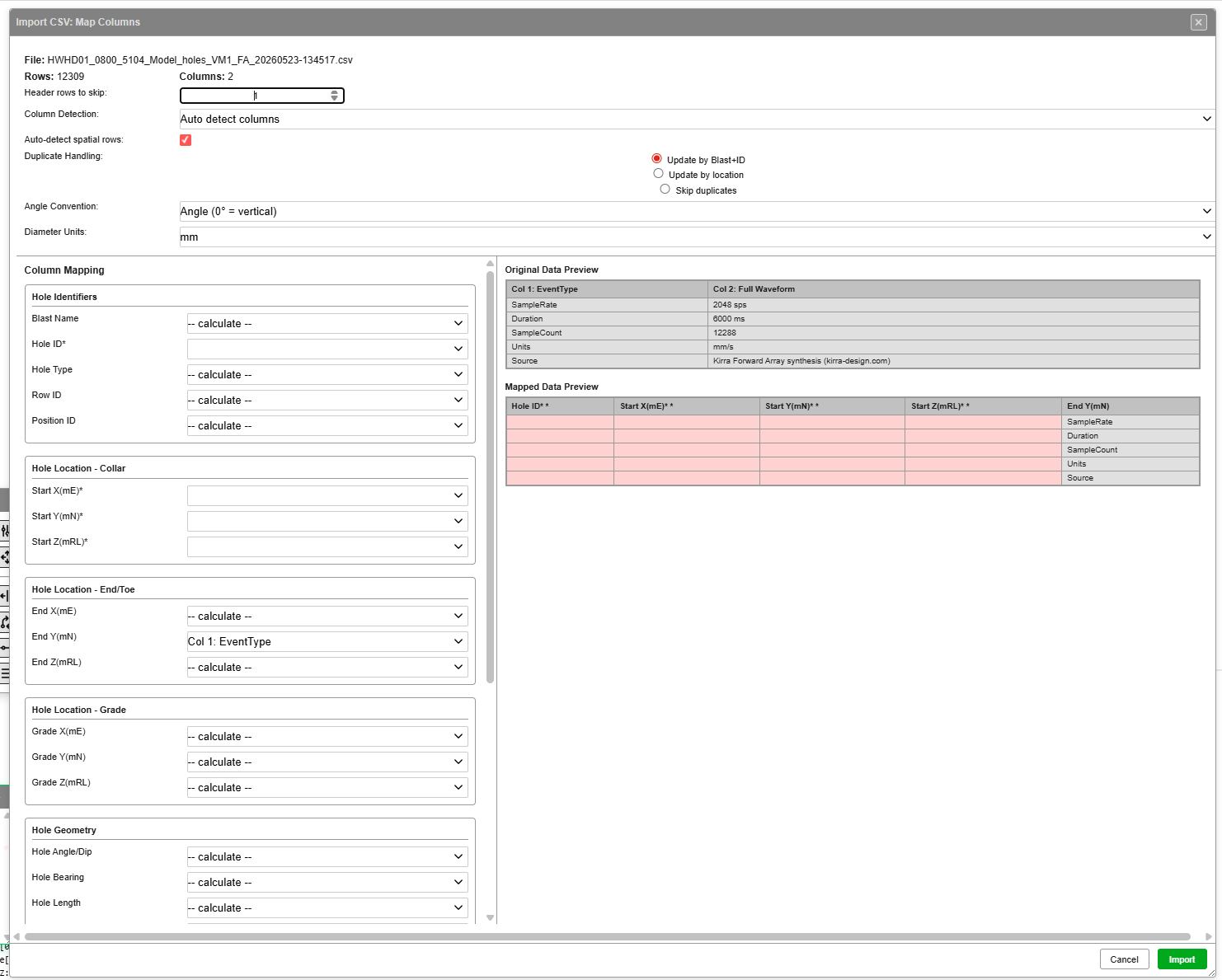 Import CSV: Map Columns — file header, dialog-wide settings, column mapping (left), and live preview (right).
Import CSV: Map Columns — file header, dialog-wide settings, column mapping (left), and live preview (right).
The dialog shows the file name and row / column counts at the top, followed by dialog-wide settings, the column mapper, and a live preview.
Dialog-wide settings
| Control | Purpose |
|---|---|
| Header rows to skip | Number of rows to ignore at the top of the file (default detected) |
| Column Detection | Dropdown — defaults to Auto detect columns (header-keyword matching); switch to manual to set every mapping yourself |
| Auto-detect spatial rows | When ticked, smart row detection assigns rowID / posID from collar XY when the file does not carry them explicitly |
| Duplicate Handling | Radio buttons — Update by Blast+ID (default), Update by location (0.01 m tolerance), Skip duplicates |
| Angle Convention | Dropdown — Angle (0° = vertical) for Kirra’s native convention, or Dip (0° = horizontal) to convert (90 − value) |
| Diameter Units | Dropdown — mm (default), m, in — values are converted to mm on import |
Column Mapping panel
The left side groups Kirra fields by category. Each row has a dropdown — pick which CSV column in the file (Col 1: <name>, Col 2: <name>, …) supplies that Kirra field, or leave it as -- calculate -- to let Kirra derive it from the other fields.
| Group | Fields |
|---|---|
| Hole Identifiers | Blast Name, Hole ID (required, marked with *), Hole Type, Row ID, Position ID |
| Hole Location - Collar | Start X (mE) *, Start Y (mN) *, Start Z (mRL) * (all required) |
| Hole Location - End/Toe | End X (mE), End Y (mN), End Z (mRL) |
| Hole Location - Grade | Grade X (mE), Grade Y (mN), Grade Z (mRL) |
| Hole Geometry | Hole Angle/Dip, Hole Bearing, Hole Length |
Required fields are marked with * and shaded pink in the preview until mapped.
Live preview panels (right side)
| Panel | Shows |
|---|---|
| Original Data Preview | Top of the source file with column names as Kirra read them |
| Mapped Data Preview | What each Kirra field will receive after the mapping is applied. Pink-highlighted cells are required fields that are not yet mapped |
Footer
| Button | Action |
|---|---|
| Cancel | Discard the mapping and close |
| Import (green) | Apply the mapping, run the parser, and load the holes |
Header auto-detection
CsvColumnAutoDetect.autoDetectColumns() scans the header row, normalises each header (lowercase, alphanumeric only), and matches against a keyword list per Kirra field. Match priority:
- Exact match
- Longest matching keyword
- Earliest column wins ties
Examples of headers Kirra recognises out of the box:
| Header in your CSV | Maps to |
|---|---|
Hole ID, HoleID, BlastHoleId |
holeID |
Easting, XEast, X |
startXLocation |
Northing, YNorth, Y |
startYLocation |
Elev, Elevation, Z, Collar Z |
startZLocation |
Bearing, Azimuth |
holeBearing |
Dip |
interpreted via angle_convention (dip-from-horizontal converts to Kirra’s angle-from-vertical as 90 − value) |
Diameter, BitSize |
holeDiameter (with unit conversion) |
If your file uses headers Kirra doesn’t recognise, you can override with a manual columnOrder mapping in the wizard.
Geometry priority
When a CSV provides multiple geometry specs at once, the parser picks the first match:
- Collar + Toe coordinates (overrides L/A/B if both present)
- Collar + Length / Angle / Bearing + Subdrill (forward calc)
- Toe + L/A/B + Subdrill (reverse calc — collar back-derived from toe)
- Collar + L/A/B only (subdrill defaults to 1)
- Collar only (length =
benchHeight + subdrill, angle = 0, bearing = 0)
Subdrill is always the vertical Δz, not along-hole.
Smart row detection
For files without explicit rowID / posID:
- Alphanumeric IDs (e.g.
A1, A2, B1) — letter becomes the row, number becomes the position - Pure numeric — fits holes to linear sequences using collar XY (tolerance
2 × diameter) - Fallback — auto-assigns when the pattern is unclear
Duplicate handling
Configurable per import:
| Mode | Behaviour |
|---|---|
update-blast-hole |
Match on entityName + holeID, overwrite existing |
update-location |
Match on collar proximity (0.01 m tolerance), overwrite existing |
skip |
Keep the first, drop subsequent duplicates |
Time → delay back-calculation
If the CSV provides absolute holeTime but no timingDelayMilliseconds, Kirra walks the timing graph and derives each delay as myTime − fromHoleTime.
Unit conversion
- Diameter —
m → mm(× 1000) orin → mm(× 25.4) on import; reverse on export - Angle —
dip-from-horizontal(90 = horizontal) converts to Kirra’sangle-from-vertical(0 = vertical) as90 − value
NaN guard
Invalid coordinates do not abort the import:
end ← collar(zero-length / dummy hole) when the toe is badgrade ← collar ± 10when the grade is bad- A user-facing report flags every row that fell back to a default
Charging columns (v1.0.270+)
When the parser sees any header matching ^(deck|primer)([A-Z][A-Za-z]*)\[(\d+)\]$ (e.g. deckType[1], primerDepth[2]) in the first row, it switches on a charging-reconstruction pass — no manual mapping needed. Each hole gets a HoleCharging rebuilt from the deck and primer cells, including verbatim fx: formula strings.
Round-trip is full for design, formulas, and primer assignments — but live formula re-evaluation does not happen on import. The imported numeric values are the source of truth until the next Apply Charge Rule runs.
For the full Custom CSV reference (every recognised header, every charging column, worked examples), see the Kirra wiki: Custom CSV Format.
Round-trip fidelity
| Round trip | Preserves | Loses |
|---|---|---|
| 14 → import → 14 | name, ID, collar/toe, diameter, type, tying, delay, colour | grade point, subdrill, measured fields, row/pos |
| 12 → import → 12 | as 14, except entityName is auto-assigned BLAST_<hex> |
grade, subdrill, measured, row/pos |
| 35 → import → 14 → 35 | re-derives grade from subdrill (small rounding drift) | rowID, posID, burden, spacing, connectorCurve |
| 35 → import → 35 | everything the parser knows about | nothing |
For lossless round-trip across Kirra sessions, prefer 35-col export — or KAP for the full project.
Edge cases and parser quirks
- Strict column count. A 9-col file is unambiguous, but a hand-crafted file with the wrong count will parse as the wrong variant. Stick to the documented variants.
- Embedded commas in quoted strings. The parser uses
String.split(",")— not an RFC-4180 tokeniser. Embedded commas inside quoted strings are not safe. If you need that, use Custom CSV. - BOM. UTF-8 BOM is stripped by the browser’s
FileReader. - Locale numbers.
parseFloat()only — comma-decimal locales (12,5) are not supported. Use period as the decimal separator. - Missing fields. Sensible defaults:
holeDiameter = 0,holeType = "Undefined",delay = 0,color = "red".
Tips
- Coordinate order — Kirra expects Easting (X), Northing (Y), Elevation (Z). For other orders, use Custom CSV.
- File encoding — UTF-8 or ASCII. Other encodings may produce garbled text.
- Decimal separator — Period (
.) only. - Units — Coordinates in metres, diameter in millimetres, delays in milliseconds. Bare numbers, no unit suffixes.
Related topics
- CSV Export
- DXF Import
- Hole Properties Reference
- Coordinate System
- Supported File Formats — full import / export matrix